 The Data Mining Forum
The Data Mining Forum 


IMPORTANT: This is the old Data Mining forum.
I keep it online so that you can read the old messages.
Please post your new messages in the new forum: https://forum2.philippe-fournier-viger.com/index.php
diffrence between maximals frequents itemset algorithms
Posted by:
djanahana
Date: March 31, 2013 03:18PM
Hello & Good morning
i would like if you don't mind to ask you this question:
"What's the diffrence between maximals frequents itemsets algorithms " ,
is it the processing time to generate the MFI ?
do they represent the same results? or the diffrence could be the algorithm steps and only ?
the raison of my question is that I see that many rescearch projects use many algorithms to generate MFI .if they represent the same results and the time is not a very important factor i really don't see th benifit for using many algorithms
thanks for reading my message
Best regards,
Edited 1 time(s). Last edit at 03/31/2013 03:18PM by djanahana.
i would like if you don't mind to ask you this question:
"What's the diffrence between maximals frequents itemsets algorithms " ,
is it the processing time to generate the MFI ?
do they represent the same results? or the diffrence could be the algorithm steps and only ?
the raison of my question is that I see that many rescearch projects use many algorithms to generate MFI .if they represent the same results and the time is not a very important factor i really don't see th benifit for using many algorithms
thanks for reading my message
Best regards,
Edited 1 time(s). Last edit at 03/31/2013 03:18PM by djanahana.
Re: diffrence between maximals frequents itemset algorithms
Posted by:
webmasterphilfv
Date: March 31, 2013 04:08PM
Hi,
The benefit is that the set of frequent maximal itemsets is usually much smaller than the set of all frequent itemsets.
For example, if there are 10 000 frequent itemsets in a database for some minsup value, there might be only 500 maximal itemsets. So you would save space to just discover the maximal itemsets.
However, there is a problem with using maximal itemsets. It is that you loose some information. It can be proven that if you have the maximal itemsets, you can regenerate all the frequent itemsets from them but the support information is lost.
An alternative to maximal itemsets that is lossless (without lost of information) is to discover closed itemsets. The set of closed itemsets is larger than the set of maximal itemsets (all maximal itemsets are closed itemsets but the reverse is not always true). If you mine closed itemsets, you can regenerate the set of all frequent itemsets with their support.
Now about your second question, algorithms for mining maximal itemsets or closed itemsets usually do not work exactly like frequent itemsets mining algorithm. For example, you could see MaxMiner, ( http://www.cs.tau.ac.il/~fiat/dmsem03/Efficiently%20mining%20long%20patterns%20from%20databases%20-%201998.pdf ) and other more recent algorithms for mining maximal itemset mining. I have not implemented them in SPMF though.
For closed itemset mining, there are several algorithms. I have implemented DCI_Closed, Charm and AprioriClose in SPMF. Some of these algorithms can be much faster than traditional frequent itemset mining algorithm because they use some strategies to directly find the closed itemsets without generating all the frequent itemsets.
Here is a picture showing the relationship between freqeutn itemset, closed itemsets and maximal itemsets:
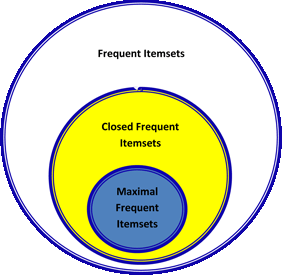 (from http://www.hypertextbookshop.com/dataminingbook/public_version/contents/chapters/chapter002/section004/blue/page002.html )
(from http://www.hypertextbookshop.com/dataminingbook/public_version/contents/chapters/chapter002/section004/blue/page002.html )
Hope this helps,
Philippe
Edited 5 time(s). Last edit at 04/01/2013 06:57AM by webmasterphilfv.
The benefit is that the set of frequent maximal itemsets is usually much smaller than the set of all frequent itemsets.
For example, if there are 10 000 frequent itemsets in a database for some minsup value, there might be only 500 maximal itemsets. So you would save space to just discover the maximal itemsets.
However, there is a problem with using maximal itemsets. It is that you loose some information. It can be proven that if you have the maximal itemsets, you can regenerate all the frequent itemsets from them but the support information is lost.
An alternative to maximal itemsets that is lossless (without lost of information) is to discover closed itemsets. The set of closed itemsets is larger than the set of maximal itemsets (all maximal itemsets are closed itemsets but the reverse is not always true). If you mine closed itemsets, you can regenerate the set of all frequent itemsets with their support.
Now about your second question, algorithms for mining maximal itemsets or closed itemsets usually do not work exactly like frequent itemsets mining algorithm. For example, you could see MaxMiner, ( http://www.cs.tau.ac.il/~fiat/dmsem03/Efficiently%20mining%20long%20patterns%20from%20databases%20-%201998.pdf ) and other more recent algorithms for mining maximal itemset mining. I have not implemented them in SPMF though.
For closed itemset mining, there are several algorithms. I have implemented DCI_Closed, Charm and AprioriClose in SPMF. Some of these algorithms can be much faster than traditional frequent itemset mining algorithm because they use some strategies to directly find the closed itemsets without generating all the frequent itemsets.
Here is a picture showing the relationship between freqeutn itemset, closed itemsets and maximal itemsets:
(from http://www.hypertextbookshop.com/dataminingbook/public_version/contents/chapters/chapter002/section004/blue/page002.html )Hope this helps,
Philippe
Edited 5 time(s). Last edit at 04/01/2013 06:57AM by webmasterphilfv.