 The Data Mining Forum
The Data Mining Forum 


IMPORTANT: This is the old Data Mining forum.
I keep it online so that you can read the old messages.
Please post your new messages in the new forum: https://forum2.philippe-fournier-viger.com/index.php
FP-Growth with infrequent itemsets !
Posted by:
Sissi
Date: April 24, 2013 06:07AM
Hi,
For my project i need to extract the frequent and infrequent itemsets using FP-Growth algorithm ...
please help me ! how do it ?
For my project i need to extract the frequent and infrequent itemsets using FP-Growth algorithm ...
please help me ! how do it ?
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: April 25, 2013 04:32PM
Hi,
The original FPGrowth algorithm takes as input a threshold named "minsup" and a transaction database.
A frequent itemset is an itemset having a support higher or equal to minsup.
FPGrowth finds all frequent itemsets.
If I understand well, you say that you want to find all frequent and infrequent itemsets at the same time. If an infrequent itemset is an itemset that is not frequent, then you could just set minsup = 0 and you will get all the itemsets.
If not sure if it is what you means.
If you are just interested by some infrequent itemset but not all of them, you could have a look at "rare itemsets" and "perfectly rare itemsets". There are some algorithms for that in SPMF.
Philippe
Edited 1 time(s). Last edit at 04/28/2013 06:41AM by webmasterphilfv.
The original FPGrowth algorithm takes as input a threshold named "minsup" and a transaction database.
A frequent itemset is an itemset having a support higher or equal to minsup.
FPGrowth finds all frequent itemsets.
If I understand well, you say that you want to find all frequent and infrequent itemsets at the same time. If an infrequent itemset is an itemset that is not frequent, then you could just set minsup = 0 and you will get all the itemsets.
If not sure if it is what you means.
If you are just interested by some infrequent itemset but not all of them, you could have a look at "rare itemsets" and "perfectly rare itemsets". There are some algorithms for that in SPMF.
Philippe
Edited 1 time(s). Last edit at 04/28/2013 06:41AM by webmasterphilfv.
Re: FP-Growth with infrequent itemsets !
Posted by:
khairy
Date: July 17, 2013 10:04AM
but in FP-Growth if am right, if we have a 100 transactions and each transaction contains frequently one item , FP-growth will give you zero frequent items, i means in FP-Growth we need at least two items in a transaction to find and get the frequent items, but in apriori you can get it. i need your valuable comments
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: July 19, 2013 07:15AM
No.
FPGrowth generates the same output as Apriori.
If you set minsup = 1 transaction, then both FPGrowth and Apriori will find all itemsets, including single items that appear in only one transaction.
FPGrowth generates the same output as Apriori.
If you set minsup = 1 transaction, then both FPGrowth and Apriori will find all itemsets, including single items that appear in only one transaction.
Re: FP-Growth with infrequent itemsets !
Posted by:
khairy
Date: July 27, 2013 12:56AM
Hi
I have tried to execute FP-Growth from SPMF. I would like to verify the calculation of the execution time for the algorithm is it for the first part:
// STEP 1: Applying the FP-GROWTH algorithm to find frequent itemsets
Itemsets patterns = fpgrowth.runAlgorithm(input, null, minsupp);
or the second part as well which is:
// STEP 2: Generating all rules from the set of frequent itemsets (based on Agrawal & Srikant, 94)
Rules rules = algoAgrawal.runAlgorithm(patterns, null, databaseSize, minconf);
because I have seen that only printStat() for FP-Growth is called however printStat for algoAgrawal is never called. Does this mean that the execution time of the second part should not be included in the total time for FP-Growth?
Regards,
I have tried to execute FP-Growth from SPMF. I would like to verify the calculation of the execution time for the algorithm is it for the first part:
// STEP 1: Applying the FP-GROWTH algorithm to find frequent itemsets
Itemsets patterns = fpgrowth.runAlgorithm(input, null, minsupp);
or the second part as well which is:
// STEP 2: Generating all rules from the set of frequent itemsets (based on Agrawal & Srikant, 94)
Rules rules = algoAgrawal.runAlgorithm(patterns, null, databaseSize, minconf);
because I have seen that only printStat() for FP-Growth is called however printStat for algoAgrawal is never called. Does this mean that the execution time of the second part should not be included in the total time for FP-Growth?
Regards,
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: July 27, 2013 05:12AM
Hi,
It means that I have forgot to call prinStats for algoAgrawal().
If you do:
fpgrowth.printStats(...)
it will only give the execution time of frequent itemset generation by FPGrowth.
If you do
algoAgrawa.printStats(...)
it will only give the execution time of association rule generation by using the frequent itemsets found previously by fpgrowth.
If you want the total time of frequent itemset mining + association rule generation, you would need to make the sum of the two execution times above.
Which execution time you need depends on what you want to compare. If you want to compare Apriori and FPGrowth for example, then you could just compare the first step because they use the same algorithm for the second step.
Philippe
It means that I have forgot to call prinStats for algoAgrawal().
If you do:
fpgrowth.printStats(...)
it will only give the execution time of frequent itemset generation by FPGrowth.
If you do
algoAgrawa.printStats(...)
it will only give the execution time of association rule generation by using the frequent itemsets found previously by fpgrowth.
If you want the total time of frequent itemset mining + association rule generation, you would need to make the sum of the two execution times above.
Which execution time you need depends on what you want to compare. If you want to compare Apriori and FPGrowth for example, then you could just compare the first step because they use the same algorithm for the second step.
Philippe
Re: FP-Growth with infrequent itemsets !
Posted by:
khairy
Date: July 27, 2013 06:44AM
Hi
one more question, when i execute any algorithm with the same support for example 5 times, the result is change, my question if i got 5 different execution time for the same minimum support, which one i have to select ?
one more question, when i execute any algorithm with the same support for example 5 times, the result is change, my question if i got 5 different execution time for the same minimum support, which one i have to select ?
Re: FP-Growth with infrequent itemsets !
Posted by:
khairy
Date: July 29, 2013 01:43PM
khairy Wrote:
Hi
one more question, when i execute any algorithm
with the same support for example 5 times, the
result is change, my question if i got 5 different
execution time for the same minimum support, which
one i have to select ?
Hi
one more question, when i execute any algorithm
with the same support for example 5 times, the
result is change, my question if i got 5 different
execution time for the same minimum support, which
one i have to select ?
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: July 29, 2013 01:51PM
It is normal that the execution time change a little bit when you execute the same algorithm several times because on your computer there is several processes running at the same time (e.g. your operating system and other software), which can interfere with the algorithm execution. Furthermore, algorithms perform disk operation (read/write). Therefore, the hard drive availability (is it used by another process on your computer), current state (where is the disk head and speed may also influence the execution time. Besides, the state of the Java virtual machine and garbage collector may also influence the time.
If you execute algorithms ith a small dataset or with very high thresholds (e.g. minsup) , the execution time may vary a lot. However, if you test algorithms with large datasets, the variation will be small.
So, if I where you, I would compare the algorithms by using large enough datasets so that the variation does not matter. If you use large datasets, then the variation does not matter.
Edited 1 time(s). Last edit at 07/29/2013 01:52PM by webmasterphilfv.
If you execute algorithms ith a small dataset or with very high thresholds (e.g. minsup) , the execution time may vary a lot. However, if you test algorithms with large datasets, the variation will be small.
So, if I where you, I would compare the algorithms by using large enough datasets so that the variation does not matter. If you use large datasets, then the variation does not matter.
Edited 1 time(s). Last edit at 07/29/2013 01:52PM by webmasterphilfv.
Re: FP-Growth with infrequent itemsets !
Posted by:
ismah
Date: July 20, 2013 07:47AM
hi,
i am implementing fp growth code for classification following code in spmf. but i run the fp growth for string it does not give any output. i want to add the code for making the transaction in descending order of the support but it give error null pointer exception where it compares the values to sort in descending order. plz tell me where the problem occurs
i am implementing fp growth code for classification following code in spmf. but i run the fp growth for string it does not give any output. i want to add the code for making the transaction in descending order of the support but it give error null pointer exception where it compares the values to sort in descending order. plz tell me where the problem occurs
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: July 20, 2013 04:04PM
Hi,
Its hard to know where the problem occurs without looking at the code and looking at the full error.
Could you paste the full error here?
If you paste the full error, maybe i can tell you what the problem may be.
Philippe
Its hard to know where the problem occurs without looking at the code and looking at the full error.
Could you paste the full error here?
If you paste the full error, maybe i can tell you what the problem may be.
Philippe
Re: FP-Growth with infrequent itemsets !
Posted by:
ismah
Date: July 20, 2013 09:17PM
the problem occurs where we extract the transaction and get the support of the item and compare it with relative support.following is the transaction
yes overcast hot high false
it gives the support of false item equal to null. that is why it gives null pointer exception . tell me how to handle it
yes overcast hot high false
it gives the support of false item equal to null. that is why it gives null pointer exception . tell me how to handle it
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: July 21, 2013 04:04AM
From what you wrote, I'm not very sure what is the problem. You seem to say that the problem occurs when reading the file in the runAlgorithm() method?
Did you change the code for reading the file? Did your input file follows the correct format?
I tested FPGrowth on the example provided in SPMF and there is no problem. So I think that maybe it is related to your input file.
Did you change the code for reading the file? Did your input file follows the correct format?
I tested FPGrowth on the example provided in SPMF and there is no problem. So I think that maybe it is related to your input file.
Apriori and FP-Growth
Posted by:
johnson chadri
Date: July 31, 2013 08:27AM
Hi
Association rule mining also can be known as market basket analysis, when we use this concept of market basket analysis in Apriori and FP-Growth we find there is a problem suppose if we take this example
1 3 4
2 3 5
1 3 4
1 2 3 5
2 5
1 3 4
2 ==> 5 sup= 3
4 ==> 3 sup= 3
1 ==> 4 sup= 3
5 ==> 2 sup= 3
4 ==> 1 sup= 3
3 ==> 4 sup= 3
3 ==> 1 4 sup= 3
4 ==> 1 3 sup= 3
1 ==> 3 4 sup= 3
3 4 ==> 1 sup= 3
1 3 ==> 4 sup= 3
1 4 ==> 3 sup= 3
3 ==> 1 sup= 4
1 ==> 3 sup= 4
this can be the output form Apriori or FP-Growth
but in fact if i want to find the association rule between a set of items his result giving error answers for example
2 ==> 5 giving sup= 3
but if we look to the association between the items
the pair items 2 ==> 5 only occur one time that means its support must be 1
some times 2 ==> 5 occurs with other items for example 1 2 3 5
but how it can be counted to increase the support of 2 ==> 5 only this means
what are the relation between the items containing 2 ==> 5 which is
2 3 5
1 2 3 5
2 5
------------------
now am implementing a new algorithm that if i give the following transactions
1 3 4
2 3 5
1 2 3 5
2 5
1 3 4
the association rules when the minimum support is 0.4 the result will be
1 3 4 only
means i will take the each transaction and find the frequency based on the given minimum support
Association rule mining also can be known as market basket analysis, when we use this concept of market basket analysis in Apriori and FP-Growth we find there is a problem suppose if we take this example
1 3 4
2 3 5
1 3 4
1 2 3 5
2 5
1 3 4
2 ==> 5 sup= 3
4 ==> 3 sup= 3
1 ==> 4 sup= 3
5 ==> 2 sup= 3
4 ==> 1 sup= 3
3 ==> 4 sup= 3
3 ==> 1 4 sup= 3
4 ==> 1 3 sup= 3
1 ==> 3 4 sup= 3
3 4 ==> 1 sup= 3
1 3 ==> 4 sup= 3
1 4 ==> 3 sup= 3
3 ==> 1 sup= 4
1 ==> 3 sup= 4
this can be the output form Apriori or FP-Growth
but in fact if i want to find the association rule between a set of items his result giving error answers for example
2 ==> 5 giving sup= 3
but if we look to the association between the items
the pair items 2 ==> 5 only occur one time that means its support must be 1
some times 2 ==> 5 occurs with other items for example 1 2 3 5
but how it can be counted to increase the support of 2 ==> 5 only this means
what are the relation between the items containing 2 ==> 5 which is
2 3 5
1 2 3 5
2 5
------------------
now am implementing a new algorithm that if i give the following transactions
1 3 4
2 3 5
1 2 3 5
2 5
1 3 4
the association rules when the minimum support is 0.4 the result will be
1 3 4 only
means i will take the each transaction and find the frequency based on the given minimum support
Re: Apriori and FP-Growth
Posted by:
johnson chadri
Date: July 31, 2013 11:22AM
is it important that the output of my algorithm and FP-Growth and Apriori to be same
Re: Apriori and FP-Growth
Posted by:
webmasterphilfv
Date: July 31, 2013 12:11PM
The result is correct.
By definition, the support of a rule X ==> Y is defined as the number of transactions that contains all items from X U Y.
Therefore, 2 ==> 5 has a support of 3 because {2} U {5} is included in 3 transactions which are :
2 3 5
1 2 3 5
2 5
It is important to know that in a transaction there is no notion of time. Therefore, whether 2 5 is bought with 3 or not in the same transactions is usually not considered important. Moreover, you should also know that items are not allowed to appear twice in a transaction.
From what I understand, you want to modify the algorithms so that the support of itemsets that are found is only counted for transactions that are an exact match. It is an interesting idea. However, it will be less tolerant to noise. For example, if you have only three customers that buy:
harrypotter1, harrypotter2, star wars 1, star wars 2
harrypotter1, harrypotter2, star wars 1, star wars 2, star war 3
harrypotter1, harrypotter2, star wars 1, star wars 2, start war 4
Then your algorithm would find 0 pattern, because no exact match could be found, even if these transactions are very similar. I think that you can miss a lot of important itemsets. That's my opinion. But maybe for some applications it could be useful to have only exact matches.
Moroever, if you want to only consider exact match, then you don't need to use apriori and fpgrowth. You could just count the support of each transaction directly by storing them in a hashtable, for example.
Edited 1 time(s). Last edit at 07/31/2013 12:13PM by webmasterphilfv.
By definition, the support of a rule X ==> Y is defined as the number of transactions that contains all items from X U Y.
Therefore, 2 ==> 5 has a support of 3 because {2} U {5} is included in 3 transactions which are :
2 3 5
1 2 3 5
2 5
It is important to know that in a transaction there is no notion of time. Therefore, whether 2 5 is bought with 3 or not in the same transactions is usually not considered important. Moreover, you should also know that items are not allowed to appear twice in a transaction.
From what I understand, you want to modify the algorithms so that the support of itemsets that are found is only counted for transactions that are an exact match. It is an interesting idea. However, it will be less tolerant to noise. For example, if you have only three customers that buy:
harrypotter1, harrypotter2, star wars 1, star wars 2
harrypotter1, harrypotter2, star wars 1, star wars 2, star war 3
harrypotter1, harrypotter2, star wars 1, star wars 2, start war 4
Then your algorithm would find 0 pattern, because no exact match could be found, even if these transactions are very similar. I think that you can miss a lot of important itemsets. That's my opinion. But maybe for some applications it could be useful to have only exact matches.
Moroever, if you want to only consider exact match, then you don't need to use apriori and fpgrowth. You could just count the support of each transaction directly by storing them in a hashtable, for example.
Edited 1 time(s). Last edit at 07/31/2013 12:13PM by webmasterphilfv.
Re: Apriori and FP-Growth
Posted by:
johnson chadri
Date: August 01, 2013 01:48AM
Thanks so much for your comment
i already implement an algorithm which consider exact match as you said, but the issue here is a comparison of my idea with Apriori, my question is that if i set the minimum support for example 0.09 for my algorithm and also for Apriori it is fair if my algorithm give a less execution time than Apriori , in case not fair, how can i validate my method with the other algorithms. also you mention that the algorithm can be useful for some applications, can you provide any suggestions.
Thanks,
i already implement an algorithm which consider exact match as you said, but the issue here is a comparison of my idea with Apriori, my question is that if i set the minimum support for example 0.09 for my algorithm and also for Apriori it is fair if my algorithm give a less execution time than Apriori , in case not fair, how can i validate my method with the other algorithms. also you mention that the algorithm can be useful for some applications, can you provide any suggestions.
Thanks,
Re: Apriori and FP-Growth
Posted by:
webmasterphilfv
Date: August 01, 2013 04:13AM
Apriori address a different problem than your algorithm. Therefore we cannot say that the comparison is fair or that your algorithm is better with respect to speed and memory. The problem of mining all itemsets is in my opinion more difficult than the problem of exact match because you are adding an additional constraint and therefore the search space is smaller for your problem.
But in my opinion it is still interesting to compare with apriori. The reason is that you are probably writing the first algorithm for exact match. Therefore, you can compare with what? If you don't have any other algorithm to compare, then I think that comparing with Apriori is relevant. The goal of the comparison would be to show how difficult it is to mine exact match compare to all itemsets rather than to show that your algorithm is better (because they don't address the same problem).
You can compare speed, memory and scalability.
For the applications, I don't have any specific idea now and I need to go do something important now. I think that you can find some.
Edited 2 time(s). Last edit at 08/01/2013 04:41AM by webmasterphilfv.
But in my opinion it is still interesting to compare with apriori. The reason is that you are probably writing the first algorithm for exact match. Therefore, you can compare with what? If you don't have any other algorithm to compare, then I think that comparing with Apriori is relevant. The goal of the comparison would be to show how difficult it is to mine exact match compare to all itemsets rather than to show that your algorithm is better (because they don't address the same problem).
You can compare speed, memory and scalability.
For the applications, I don't have any specific idea now and I need to go do something important now. I think that you can find some.
Edited 2 time(s). Last edit at 08/01/2013 04:41AM by webmasterphilfv.
Re: Apriori and FP-Growth
Posted by:
johnson chadri
Date: August 02, 2013 09:40PM
thanks for valuable informations
i tried to search for similar approaches under the search title
exact match association rules
data mining exact match
frequent pattern exact match
but unfortunately i didn't found a related papers
????
i tried to search for similar approaches under the search title
exact match association rules
data mining exact match
frequent pattern exact match
but unfortunately i didn't found a related papers
????
Re: Apriori and FP-Growth
Posted by:
webmasterphilfv
Date: August 03, 2013 03:35AM
Maybe there is no paper on this topic.
Or maybe that they don't use the term "exact match" but another term.
Often, the problem when doing a literature review is to find the right keywords for searching.
When I was writing to you, I said "exact match". But I have no idea maybe someone else will call that with a different name.
I cannot help you about that. The only way to know is to keep searching and try other keywords.
Or maybe that they don't use the term "exact match" but another term.
Often, the problem when doing a literature review is to find the right keywords for searching.
When I was writing to you, I said "exact match". But I have no idea maybe someone else will call that with a different name.
I cannot help you about that. The only way to know is to keep searching and try other keywords.
Re: Apriori and FP-Growth
Posted by:
Arpit Varma
Date: November 25, 2013 07:15AM
I was performing comparative study between Apriori and Fp Growth algorithms implemented in Spmf for my college project. I took data set of 10,000 transactions with each transaction having up to 100 elements. It turns out Apriori is running more efficiently than Fp Growth when you look at the running time and memory usage.
Can someone please briefly explain why isn't FP growth Not running faster than Apriori? Should I change the input sets for better results?
Can someone please briefly explain why isn't FP growth Not running faster than Apriori? Should I change the input sets for better results?
Re: Apriori and FP-Growth
Posted by:
webmasterphilfv
Date: November 25, 2013 11:00AM
Hello,
Here are the most likely answers:
- you probably did not set the minsup threshold low enough. Usually Apriori can be faster than FPGrowth for some datasets if minsup is very high. If you try to lower minsup, there is a high chance that FPGrowth will become faster. Usually to compare two algorithms, you should try to push them to their limits. As a rule of thumb, if the algorithm execute in less than 5 or 10 minutes for the minsup value that you chose, it probably means that you should use a lower minsup value.
- Not all datasets are the same. Depending on the number of items, the transaction length, the dataset is dense or sparse, transactions are similar or not, the minsup threshold, etc., the performance of algorithms will vary. So it is possible that Apriori is faster in some special cases although FPGrowth is generally a much faster algorithm. To understand why, you need to know that they use two different approaches to discover patterns. Apriori use a candidate generation approach which has the drawback of generating patterns not appearing in the database. FPGrowth use a pattern growth approach, which has the drawback of performing multiple database projections but it has the advantages of not generating candidates. The relative performance of FPGrowth and Apriori depends on how these advantages/drawbacks are important with respect to each other for your dataset.
- Besides, data mining researchers usually compare two algorithms by using several datasets since the performance vary depending on the dataset. You can get more datasets on the dataset page of SPMF.
By the way, please don't copy-paste your questions in several threads of the forum and send it to several of my e-mails. I receive a notification for every forum post and check all my e-mails daily. I will not answer faster because I receive multiple e-mails.
Best
Philippe
Edited 1 time(s). Last edit at 11/25/2013 11:01AM by webmasterphilfv.
Here are the most likely answers:
- you probably did not set the minsup threshold low enough. Usually Apriori can be faster than FPGrowth for some datasets if minsup is very high. If you try to lower minsup, there is a high chance that FPGrowth will become faster. Usually to compare two algorithms, you should try to push them to their limits. As a rule of thumb, if the algorithm execute in less than 5 or 10 minutes for the minsup value that you chose, it probably means that you should use a lower minsup value.
- Not all datasets are the same. Depending on the number of items, the transaction length, the dataset is dense or sparse, transactions are similar or not, the minsup threshold, etc., the performance of algorithms will vary. So it is possible that Apriori is faster in some special cases although FPGrowth is generally a much faster algorithm. To understand why, you need to know that they use two different approaches to discover patterns. Apriori use a candidate generation approach which has the drawback of generating patterns not appearing in the database. FPGrowth use a pattern growth approach, which has the drawback of performing multiple database projections but it has the advantages of not generating candidates. The relative performance of FPGrowth and Apriori depends on how these advantages/drawbacks are important with respect to each other for your dataset.
- Besides, data mining researchers usually compare two algorithms by using several datasets since the performance vary depending on the dataset. You can get more datasets on the dataset page of SPMF.
By the way, please don't copy-paste your questions in several threads of the forum and send it to several of my e-mails. I receive a notification for every forum post and check all my e-mails daily. I will not answer faster because I receive multiple e-mails.
Best
Philippe
Edited 1 time(s). Last edit at 11/25/2013 11:01AM by webmasterphilfv.
Re: FP-Growth with infrequent itemsets !
Posted by:
khairy
Date: November 26, 2013 05:55AM
i want to do association rule case study for market basket analysis using any dataset like retail dataset, but my issue, i need dataset that having manual or any definition for the items because when i finished i want to analysis the association and i do not want to say for example
association frequency confident lift correlation
232 8485 230 ------ 0.132455
in the analysis i want to say 232 which milk have strong association with 8485 which is sugar
no problem the dataset can be be a number format but there must be some definitions for the items
thanks in advance
association frequency confident lift correlation
232 8485 230 ------ 0.132455
in the analysis i want to say 232 which milk have strong association with 8485 which is sugar
no problem the dataset can be be a number format but there must be some definitions for the items
thanks in advance
Re: FP-Growth with infrequent itemsets !
Posted by:
Philippe
Date: November 26, 2013 06:04AM
I know that there is a dataset named FOODMART included with SQL Server 2000 and 2005, and maybe other versions.
I don't have it. But I have heard that it includes many aditional information such as the price of items and their quantities in transactions. I have read some papers about people who have used foodmart for itemset mining.
If you can find it, it should be some SQL tables, so you would probably have to convert it to SPMF format.
Best,
Philippe
I don't have it. But I have heard that it includes many aditional information such as the price of items and their quantities in transactions. I have read some papers about people who have used foodmart for itemset mining.
If you can find it, it should be some SQL tables, so you would probably have to convert it to SPMF format.
Best,
Philippe
Re: FP-Growth with infrequent itemsets !
Posted by:
Philippe
Date: November 26, 2013 06:11AM
The MySQL dump of Foodmart can be obtained here:
https://raw.github.com/rsim/mondrian_demo/master/db/foodmart.sql
I think you can use that to import FOODMART in a new MySQL database.
https://raw.github.com/rsim/mondrian_demo/master/db/foodmart.sql
I think you can use that to import FOODMART in a new MySQL database.
Re: FP-Growth with infrequent itemsets !
Posted by:
khairy
Date: December 14, 2013 02:17AM
i designed a new algorithm for mining the frequent items and association rule generation to validate my own algorithm with the two famous algorithms FP-Growth and Apriori using SPMF codes
when i run FP-Growth algorithm it seem there is two measure of execution time
one for Frequent itemsets
two association rules generation
to measure it with my algorithm i have to sum the two times together this is clear for FP-Grwoth , but how can i measure my algorithm with apriori which give only one execution time as provided by SPMF. because the two time available in FP-Grwoth will be max than the one time in Apriori which is unfair to be measure criteria.
when i run FP-Growth algorithm it seem there is two measure of execution time
one for Frequent itemsets
two association rules generation
to measure it with my algorithm i have to sum the two times together this is clear for FP-Grwoth , but how can i measure my algorithm with apriori which give only one execution time as provided by SPMF. because the two time available in FP-Grwoth will be max than the one time in Apriori which is unfair to be measure criteria.
Re: FP-Growth with infrequent itemsets !
Posted by:
Philippe
Date: December 14, 2013 03:31AM
There is two versions of Apriori in SPMF.
(1) "Apriori" is for frequent itemset generation (step1 only) (described in Example #1)
(2) "Apriori_association rules" is for also generating association rules (step 1 + step 2) (described very briefly in Example 22 - implementation details)
By running "Apriori_association rules" in the GUI you should get the execution times for Step1 + step2 (you would need to double check).
Best,
Philippe
(1) "Apriori" is for frequent itemset generation (step1 only) (described in Example #1)
(2) "Apriori_association rules" is for also generating association rules (step 1 + step 2) (described very briefly in Example 22 - implementation details)
By running "Apriori_association rules" in the GUI you should get the execution times for Step1 + step2 (you would need to double check).
Best,
Philippe
not able to execute the programs
Posted by:
sharada narra
Date: February 16, 2014 07:51AM
Please let me know the reason for the following message when i tried to run the programs in eclipse.
"Selection does not have a main type"
Sharada N
"Selection does not have a main type"
Sharada N
Re: not able to execute the programs
Posted by:
webmasterphilfv
Date: February 16, 2014 08:49AM
In general, it means that the file has no "main" method.
But if the file has a "main" method, it most likely means that you have not installed the source code correctly and that the class is not on the package where it should be.
For example, in Eclipse, there should be a /src/ folder in your project.
In the source folder, you should have copied the whole /ca/ folder from the SPMF source code when installing the source code.
If you just copied some java files without the hierarchy of folders, then Eclipse will not recognize the classes as being in their folder (package) and it will make that error.
A quick solution to solve this problem is to create a new project and follow the instructions step by step to make sure that you install the source code correctly.
Philippe
But if the file has a "main" method, it most likely means that you have not installed the source code correctly and that the class is not on the package where it should be.
For example, in Eclipse, there should be a /src/ folder in your project.
In the source folder, you should have copied the whole /ca/ folder from the SPMF source code when installing the source code.
If you just copied some java files without the hierarchy of folders, then Eclipse will not recognize the classes as being in their folder (package) and it will make that error.
A quick solution to solve this problem is to create a new project and follow the instructions step by step to make sure that you install the source code correctly.
Philippe
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 10, 2015 01:18AM
I am implementing FP-growth algorithm to generate association rules in javaswing.It is not working for a large dataset of 2543*20.When i am giving a input of 9 rows and 5 columns,it generates associations which are not understood.
This is the dataset i given randomly,
Tat Nef Capsid env_gp120 Gag_Pr55
yes yes yes yes yes
yes yes yes yes yes
yes yes yes yes yes
yes yes yes yes yes
yes yes yes yes yes
Given a output of associations :
{ 507}->{ 1507}
{ 1507}->{ 507}
{ 507}->{ 2507}
{ 2507}->{ 507}
{ 1507}->{ 2507}
But i need the associations rules in terms of (tat,nef capsid,env_gv120,GagPr_55).What to do and why the input is not accepting large data sets?
pls help...
This is the dataset i given randomly,
Tat Nef Capsid env_gp120 Gag_Pr55
yes yes yes yes yes
yes yes yes yes yes
yes yes yes yes yes
yes yes yes yes yes
yes yes yes yes yes
Given a output of associations :
{ 507}->{ 1507}
{ 1507}->{ 507}
{ 507}->{ 2507}
{ 2507}->{ 507}
{ 1507}->{ 2507}
But i need the associations rules in terms of (tat,nef capsid,env_gv120,GagPr_55).What to do and why the input is not accepting large data sets?
pls help...
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: February 10, 2015 04:15AM
The performance of FPGrowth depends on the number of patterns. Even if you have a small database with just 2 transactions, FPGrowth may never terminates if the number of patterns is too high. And FPGrowth may run fine with millions of transactions if the number of patterns is small.
What really influence the performance of FPGrowth is:
- is your transactions similar or not
- is your transactions really long or not
- is there few items in your transactions
- how similar transactions are to each other
- how you set the minsup threshold... if you set it too low, the number of patterns may increase exponentially
In general, the more your data is dense and the more minsup is low, the more there will be patterns, and the more FPGrowth will be slow.
What really influence the performance of FPGrowth is:
- is your transactions similar or not
- is your transactions really long or not
- is there few items in your transactions
- how similar transactions are to each other
- how you set the minsup threshold... if you set it too low, the number of patterns may increase exponentially
In general, the more your data is dense and the more minsup is low, the more there will be patterns, and the more FPGrowth will be slow.
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 15, 2015 09:19PM
{ 1544}->{ 4544}
{ 2544 1544}->{ 4544}
{ 1544}->{ 2544 4544}
{ 3544 4544 1544}->{ 6544}
{ 2544 3544 4544 1544}->{ 6544}
{ 3544 4544 1544}->{ 2544 6544}
{ 3544 544 4544 1544}->{ 6544}
{ 2544 3544 544 4544 1544}->{ 6544}
sir,i am getting the rules like this,but i need only for the itemset=2.how to extract from these rules?
{ 2544 1544}->{ 4544}
{ 1544}->{ 2544 4544}
{ 3544 4544 1544}->{ 6544}
{ 2544 3544 4544 1544}->{ 6544}
{ 3544 4544 1544}->{ 2544 6544}
{ 3544 544 4544 1544}->{ 6544}
{ 2544 3544 544 4544 1544}->{ 6544}
sir,i am getting the rules like this,but i need only for the itemset=2.how to extract from these rules?
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: February 16, 2015 05:17AM
Hi,
I'm not sure to understand.
You want rules containing the item "2" such as 2 -> 4 5 6?
Or your want rules containing only two itemss such as 4 -> 5 ?
If you tell me more cleary, maybe I can help you about that
Best,
I'm not sure to understand.
You want rules containing the item "2" such as 2 -> 4 5 6?
Or your want rules containing only two itemss such as 4 -> 5 ?
If you tell me more cleary, maybe I can help you about that
Best,
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 19, 2015 05:12AM
I want the rules of only items
A->B
How to do it?
A->B
How to do it?
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 22, 2015 02:17AM
My csv file consists of both yes and no values.
I want to read my csv file of only "yes" values.I have used
CSVReader csvr = new CSVReader(new FileReader(path));
csvr.readAll();
Here i have any possibilities of giving any condition to get only "yes" values?
I want to read my csv file of only "yes" values.I have used
CSVReader csvr = new CSVReader(new FileReader(path));
csvr.readAll();
Here i have any possibilities of giving any condition to get only "yes" values?
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: February 22, 2015 04:54AM
I don't use CSVReader but by quickly checking the documentation.
http://opencsv.sourceforge.net/apidocs/au/com/bytecode/opencsv/CSVReader.html
the readNext() method returns lines as an array of String.
Then you could do a for loop. For example:
List<String[]> lines = cvsr.readNext();
for(String[] line : lines){
// for each value
for(String value : line){
if("yes".equals(value){
// do something
}
}
}
I think it would be something like that. But by the way, I did not compile this code. It is just the main idea.
http://opencsv.sourceforge.net/apidocs/au/com/bytecode/opencsv/CSVReader.html
the readNext() method returns lines as an array of String.
Then you could do a for loop. For example:
List<String[]> lines = cvsr.readNext();
for(String[] line : lines){
// for each value
for(String value : line){
if("yes".equals(value){
// do something
}
}
}
I think it would be something like that. But by the way, I did not compile this code. It is just the main idea.
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 22, 2015 06:30AM
It will show error,becoz readNext() will be used for "Strings",but u declared "List".
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: February 22, 2015 07:47AM
you use readAll() instead
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 22, 2015 07:04PM
When i am using readall(),all values were being used.But i need only "yes" rules.any idea?
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: February 22, 2015 07:12PM
If you use the code that I had posted and replace with readall:
List<String[]> lines = cvsr.readall();
for(String[] line : lines){
// for each value
for(String value : line){
if("yes".equals(value){
// do something
}
}
}
then the line containing the IF statement will take care of checking whether a value is YES or NO. Inside that IF statement, you will detect all the YES and then you can do whatever you want with the YES.
List<String[]> lines = cvsr.readall();
for(String[] line : lines){
// for each value
for(String value : line){
if("yes".equals(value){
// do something
}
}
}
then the line containing the IF statement will take care of checking whether a value is YES or NO. Inside that IF statement, you will detect all the YES and then you can do whatever you want with the YES.
Re: FP-Growth with infrequent itemsets !
Posted by:
Vikram
Date: December 05, 2015 07:40AM
Can we also read Excel files?
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 23, 2015 09:44PM
Sir,I have generated association rules,but want to classify into two groups.How to do?...any idea..
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: February 24, 2015 06:38AM
What are the groups? What is your goal?
If I don't know what is your goal it is hard to suggest something. There is a lof of different ways that you could put rules into groups. For example, you could just group them according to their size or according to their confidence. But it would maybe not make sense for your goal.
If I don't know what is your goal it is hard to suggest something. There is a lof of different ways that you could put rules into groups. For example, you could just group them according to their size or according to their confidence. But it would maybe not make sense for your goal.
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 25, 2015 06:47PM
I have found rules for HIV and Human proteins.now ,i need to classify into interacting and non-interacting groups with the rules i have generated.And to determine,how much percentage,did the human and hiv proteins interacting?
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: February 25, 2015 07:49PM
Looks like an interesting topic! I cannot help you too much about that because I know nothing about bioinformatics!
But hope you can get some good results!
But hope you can get some good results!
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: February 26, 2015 01:05AM
Thank you sir!!
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: March 03, 2015 06:26AM
I need a weka implementation of FP-growth algorithm sir in java
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: March 03, 2015 06:10PM
i have extracted FP-growth algorithm from weka..but i need to execute this fp-growth in separate java file to execute...pls help sir
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: March 03, 2015 08:28PM
Hi,
I don't use Weka. The FPGrowth implementation of Weka is slow.
I did some experiments a while ago, and the FPGrowth implementation offered in SPMF is much faster.
For example:
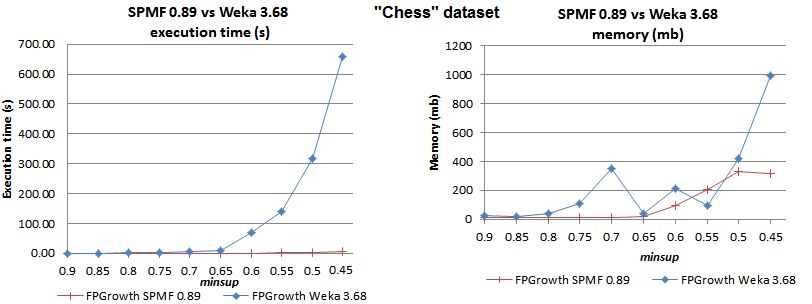
Edited 1 time(s). Last edit at 03/03/2015 08:29PM by webmasterphilfv.
I don't use Weka. The FPGrowth implementation of Weka is slow.
I did some experiments a while ago, and the FPGrowth implementation offered in SPMF is much faster.
For example:
Edited 1 time(s). Last edit at 03/03/2015 08:29PM by webmasterphilfv.
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: March 03, 2015 09:20PM
I tried with that,but no data supplied is showing.No rules are generated
Re: FP-Growth with infrequent itemsets !
Posted by:
Luc
Date: November 13, 2015 02:32PM
Need source code
Re: FP-Growth with infrequent itemsets !
Posted by:
malarvizhi
Date: March 03, 2015 11:27PM
Sir,i didnt find the Association rule mining of Fp-growth itemsets with strings?
Re: FP-Growth with infrequent itemsets !
Posted by:
Lina
Date: August 07, 2015 11:39PM
Sir, I want to ask about the result of FP-Growth. Did redundant rules have removed/pruned?
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: August 08, 2015 03:17AM
It depends how you define redundancy.
If you mean that a rule is redundant if it is found twice, then you can say yes, because using FPGrowth in SPMF, you will not get the same rule twice.
However, if you define "redundancy" as a rule that is included in another rule. For example a -> b can be seen as a special case of the rule a-> b c, then using FPGrowth in SPMF will discover both rules.
There are some specific algorithms for finding non-redundant association rules. You may have a look at the documentation in SPMF. Several algorithms will define what is "redundancy" differently.
Best,
If you mean that a rule is redundant if it is found twice, then you can say yes, because using FPGrowth in SPMF, you will not get the same rule twice.
However, if you define "redundancy" as a rule that is included in another rule. For example a -> b can be seen as a special case of the rule a-> b c, then using FPGrowth in SPMF will discover both rules.
There are some specific algorithms for finding non-redundant association rules. You may have a look at the documentation in SPMF. Several algorithms will define what is "redundancy" differently.
Best,
Re: FP-Growth with infrequent itemsets !
Posted by:
Anonymous User
Date: November 26, 2015 04:34AM
Sissi Wrote:
-------------------------------------------------------
> Hi,
> For my project i have executed in weka and have the following output:
[a7=true, class=c1]: 19 ==> [a5=true]: 19 <conf 1)> lift1.79) lev0.08) conv8.36)
1)> lift1.79) lev0.08) conv8.36)
What does it mean
-------------------------------------------------------
> Hi,
> For my project i have executed in weka and have the following output:
[a7=true, class=c1]: 19 ==> [a5=true]: 19 <conf
1)> lift1.79) lev0.08) conv8.36)What does it mean
Re: FP-Growth with infrequent itemsets !
Posted by:
Pedr
Date: January 21, 2016 06:29PM
I want more information about infrequent weighted itemset mining. What is the best algorithm for IWIM??
Re: FP-Growth with infrequent itemsets !
Posted by:
sayli
Date: January 26, 2016 11:01PM
I am unable to run the code in eclipse...
i want to execute the fpgrowth algorithm where i need to show the fptree ..
revert asap
i want to execute the fpgrowth algorithm where i need to show the fptree ..
revert asap
Re: FP-Growth with infrequent itemsets !
Posted by:
webmasterphilfv
Date: January 27, 2016 02:14AM
Hi, if you are using the FPGrowth code from the SPMF library you can print the tree to the console as follow:
// create the tree FPTree tree = new FPTree(); ... //... do something else //... // Then, when you want to print the tree, you do: System.out.println(tree.toString);
Re: FP-Growth with frequent itemsets !
Posted by:
Ajith Sivadas
Date: April 21, 2016 03:53AM
Hai...
Can u help me to handle FP-Growth algorithm for Strings instead of number values?
Can u help me to handle FP-Growth algorithm for Strings instead of number values?
Re: FP-Growth with frequent itemsets !
Posted by:
webmasterphilfv
Date: April 21, 2016 05:59AM
In the package:
ca.pfv.spmf.algorithms.frequentpatterns.fpgrowth_with_strings;
of SPMF, you will find the class file:
AlgoFPGrowth_Strings
that is FPGrowth with strings.
ca.pfv.spmf.algorithms.frequentpatterns.fpgrowth_with_strings;
of SPMF, you will find the class file:
AlgoFPGrowth_Strings
that is FPGrowth with strings.
Re: FP-Growth with infrequent itemsets !
Posted by:
pant madhuri
Date: July 03, 2016 08:55PM
results in weka for apriori output is with true and in fp growth output is with false what to do to get same results i.e. results with true outputs